Un exemple de calcul de corrélation, de construction de régression linéaire et de test de l'hypothèse de dépendance de deux SV en utilisant notre service. Analyse de corrélation et de régression dans Excel : instructions d'exécution
L'article d'aujourd'hui expliquera comment les variables peuvent être liées les unes aux autres. Grâce à la corrélation, nous pouvons déterminer s'il existe une relation entre la première et la deuxième variable. J'espère que vous trouverez cette activité aussi amusante que les précédentes !
La corrélation mesure la force et la direction de la relation entre x et y. La figure montre différents types de corrélation sous forme de nuages de points de paires ordonnées (x, y). Traditionnellement, la variable x est placée sur l'axe horizontal et la variable y est placée sur l'axe vertical.

Le graphique A est un exemple de corrélation linéaire positive : à mesure que x augmente, y augmente également, et de manière linéaire. Le graphique B nous montre un exemple de corrélation linéaire négative, où à mesure que x augmente, y diminue linéairement. Dans le graphique C, nous voyons qu’il n’y a pas de corrélation entre x et y. Ces variables ne s’influencent en aucune façon.
Enfin, le graphique D est un exemple de relations non linéaires entre variables. À mesure que x augmente, y diminue d’abord, puis change de direction et augmente.
Le reste de l'article se concentre sur les relations linéaires entre les variables dépendantes et indépendantes.
Coefficient de corrélation
Le coefficient de corrélation, r, nous fournit à la fois la force et la direction de la relation entre les variables indépendantes et dépendantes. Les valeurs de r varient entre - 1,0 et + 1,0. Quand r a valeur positive, la relation entre x et y est positive (graphique A sur la figure), et lorsque la valeur de r est négative, la relation est également négative (graphique B). Un coefficient de corrélation proche de zéro indique qu'il n'y a pas de relation entre x et y (graphique C).
La force de la relation entre x et y est déterminée selon que le coefficient de corrélation est proche de - 1,0 ou de +- 1,0. Étudiez le dessin suivant.

Le graphique A montre une corrélation positive parfaite entre x et y à r = + 1,0. Graphique B - corrélation négative idéale entre x et y à r = - 1,0. Les graphiques C et D sont des exemples de relations plus faibles entre les variables dépendantes et indépendantes.
Le coefficient de corrélation, r, détermine à la fois la force et la direction de la relation entre les variables dépendantes et indépendantes. Les valeurs r vont de - 1,0 (forte relation négative) à + 1,0 (forte relation positive). Lorsque r = 0, il n'y a aucun lien entre les variables x et y.
Nous pouvons calculer rapport réel corrélations à l’aide de l’équation suivante :

Eh bien, eh bien ! Je sais que cette équation ressemble à un fouillis effrayant de symboles étranges, mais avant de paniquer, appliquons-y l'exemple d'une note d'examen. Disons que je souhaite déterminer s'il existe une relation entre le nombre d'heures qu'un étudiant consacre à l'étude des statistiques et la note obtenue à l'examen final. Le tableau ci-dessous nous aidera à décomposer cette équation en plusieurs calculs simples et à les rendre plus gérables.

![]()

Comme vous pouvez le constater, il existe une très forte corrélation positive entre le nombre d’heures consacrées à l’étude d’une matière et la note obtenue à l’examen. Les enseignants seront très heureux de le savoir.
Quel est l’avantage d’établir des relations entre des variables similaires ? Excellente question. Si une relation existe, nous pouvons prédire les résultats des examens en fonction d’un certain nombre d’heures passées à étudier le sujet. En termes simples, plus la connexion est forte, plus notre prédiction sera précise.
Utiliser Excel pour calculer les coefficients de corrélation
Je suis sûr qu'après avoir regardé ces terribles calculs de coefficients de corrélation, vous serez vraiment ravi de savoir qu'Excel peut faire tout ce travail pour vous en utilisant la fonction CORREL avec les caractéristiques suivantes :
CORREL (tableau 1 ; tableau 2),
tableau 1 = plage de données pour la première variable,
tableau 2 = plage de données pour la deuxième variable.
Par exemple, la figure montre la fonction CORREL utilisée pour calculer le coefficient de corrélation pour l'exemple de note d'examen.

Avec connexion de corrélationà la même valeur d'une caractéristique correspond des valeurs différentes d'une autre. Par exemple : il existe une corrélation entre la taille et le poids, entre l'incidence des tumeurs malignes et l'âge, etc.
Il existe 2 méthodes pour calculer le coefficient de corrélation : la méthode des carrés (Pearson), la méthode des rangs (Spearman).
La plus précise est la méthode des carrés (Pearson), dans laquelle le coefficient de corrélation est déterminé par la formule : , où
r xy est le coefficient de corrélation entre les séries statistiques X et Y.
d x est l'écart de chacun des nombres de la série statistique X par rapport à sa moyenne arithmétique.
d y est l'écart de chacun des nombres de la série statistique Y par rapport à sa moyenne arithmétique.
Selon la force de la connexion et sa direction, le coefficient de corrélation peut aller de 0 à 1 (-1). Un coefficient de corrélation de 0 indique une absence totale de connexion. Plus le niveau du coefficient de corrélation est proche de 1 ou (-1), plus le direct ou le feedback qu'il mesure est d'autant plus grand et plus précis. Lorsque le coefficient de corrélation est égal à 1 ou (-1), la connexion est complète et fonctionnelle.
Schéma d'évaluation de la force de corrélation à l'aide du coefficient de corrélation
|
Le pouvoir de la connexion |
La valeur du coefficient de corrélation si disponible |
|
|
connexion directe (+) |
retour (-) |
|
|
Aucune connexion | ||
|
La connexion est petite (faible) |
de 0 à +0,29 |
de 0 à –0,29 |
|
Connexion moyenne (modérée) |
de +0,3 à +0,69 |
de –0,3 à –0,69 |
|
La connexion est grande (forte) |
de +0,7 à +0,99 |
de –0,7 à –0,99 |
|
Communication complète (fonctionnel) | ||
Pour calculer le coefficient de corrélation par la méthode des carrés, un tableau de 7 colonnes est établi. Examinons le processus de calcul à l'aide d'un exemple :
DÉTERMINER LA FORCE ET LA NATURE DE LA CONNEXION ENTRE
|
Il est temps- ness goitre (V oui ) |
d X = V x –M x |
d y= V oui –M oui |
d x d oui |
d x 2 |
d oui 2 |
|
|
Σ -1345 ,0 |
Σ 13996 ,0 |
Σ 313 , 47 |
1. Déterminez la teneur moyenne en iode de l'eau (en mg/l).
 mg/l
mg/l
2. Déterminez l’incidence moyenne du goitre en %.

3. Déterminez l'écart de chaque V x par rapport à M x, c'est-à-dire dx.
201-138=63 ; 178-138=40, etc.
4. De même, nous déterminons l'écart de chaque V y par rapport à M y, c'est-à-dire d y.
0,2–3,8=-3,6 ; 0,6–38=-3,2, etc.
5. Déterminez les produits des écarts. Nous résumons le produit résultant et obtenons.

6. Nous mettons au carré d x et résumons les résultats, nous obtenons.

7. De même, on met au carré d y, on résume les résultats, on obtient

8. Enfin, nous substituons tous les montants reçus dans la formule :

Pour résoudre le problème de la fiabilité du coefficient de corrélation, son erreur moyenne est déterminée à l'aide de la formule :

(Si le nombre d’observations est inférieur à 30, alors le dénominateur est n–1).
Dans notre exemple

La valeur du coefficient de corrélation est considérée comme fiable si elle est au moins 3 fois supérieure à son erreur moyenne.
Dans notre exemple 
Ainsi, le coefficient de corrélation n’est pas fiable, ce qui nécessite une augmentation du nombre d’observations.
Le coefficient de corrélation peut être déterminé d'une manière légèrement moins précise, mais beaucoup plus simple : la méthode des rangs (Spearman).
Méthode de Spearman : P=1-(6∑d 2 /n-(n 2 -1))
créer deux rangées de caractéristiques comparables appariées, désignant respectivement la première et la deuxième rangée x et y. Dans ce cas, présentez la première ligne de la caractéristique par ordre décroissant ou croissant, et placez les valeurs numériques de la deuxième ligne en face des valeurs de la première ligne auxquelles elles correspondent
remplacer la valeur de la caractéristique dans chacune des séries comparées par un numéro d'ordre (rang). Les rangs, ou nombres, indiquent les emplacements des indicateurs (valeurs) des première et deuxième lignes. Dans ce cas, les rangs doivent être attribués aux valeurs numériques de la deuxième caractéristique dans le même ordre que celui adopté lors de leur attribution aux valeurs de la première caractéristique. Avec les mêmes valeurs d'une caractéristique dans une série, les rangs doivent être déterminés comme le nombre moyen à partir de la somme des numéros de série de ces valeurs
déterminer la différence de rang entre x et y (d) : d = x - y
mettre au carré la différence de rang résultante (d 2)
obtenir la somme des carrés de la différence (Σ d 2) et substituer les valeurs résultantes dans la formule :
Exemple:à l'aide de la méthode du classement, établir la direction et la force de la relation entre les années d'expérience de travail et la fréquence des blessures si les données suivantes sont obtenues :
Justification du choix de la méthode : Pour résoudre le problème, seule la méthode de corrélation de rang peut être choisie, car La première rangée de l'attribut « expérience professionnelle en années » comporte des options ouvertes (expérience professionnelle jusqu'à 1 an et 7 ans ou plus), ce qui ne permet pas l'utilisation d'une méthode plus précise - la méthode des carrés - pour établir un lien entre les caractéristiques comparées.
Solution. La séquence de calculs est présentée dans le texte, les résultats sont présentés sous forme de tableau. 2.
Tableau 2
|
Expérience professionnelle en années |
Nombre de blessés |
Nombres ordinaux (rangs) |
Différence de classement |
Différence de rang au carré |
|
|
d(x-y) |
d 2 |
||||
Chacune des lignes de caractéristiques appariées est désignée par « x » et « y » (colonnes 1-2).
La valeur de chaque caractéristique est remplacée par un numéro de rang (ordinal). L'ordre de répartition des rangs dans la ligne « x » est le suivant : la valeur minimale de l'attribut (expérience jusqu'à 1 an) se voit attribuer le numéro de série « 1 », les variantes suivantes de la même ligne d'attribut, respectivement, dans ordre croissant, 2ème, 3ème, 4ème et 5ème numéros de série - rangs (voir colonne 3). Un ordre similaire est suivi lors de la distribution des classements au deuxième attribut « y » (colonne 4). Dans les cas où il existe plusieurs options d'égale ampleur (par exemple, dans le problème standard, il s'agit de 12 et 12 blessures pour 100 travailleurs avec une expérience de 3-4 ans et 5-6 ans, le numéro de série est désigné par le nombre moyen à partir de la somme de leurs numéros de série. Lors du classement, les données sur le nombre de blessures (12 blessures) devraient occuper 2 et 3 places, donc leur nombre moyen est (2 + 3)/2 = 2,5. des blessures est « 12 » et « 12 » (attribut), les mêmes numéros de rang doivent être distribués - « 2,5 » (colonne 4).
Déterminer la différence de rang d = (x - y) - (colonne 5)
Mettez au carré la différence de rang (d 2) et obtenez la somme des carrés de la différence de rang Σ d 2 (colonne 6).
Calculez le coefficient de corrélation de rang à l'aide de la formule :
 où n est le nombre de paires d'options comparées dans la ligne « x » et dans la ligne « y »
où n est le nombre de paires d'options comparées dans la ligne « x » et dans la ligne « y »
Calculons le coefficient de corrélation et la covariance pour différents types relations de variables aléatoires.
Coefficient de corrélation(critère de corrélation Pearson, anglais Coefficient de corrélation du moment du produit Pearson) détermine le degré linéaire relations entre variables aléatoires.
Comme il ressort de la définition, pour calculer coefficient de corrélation il est nécessaire de connaître la distribution des variables aléatoires X et Y. Si les distributions sont inconnues, alors pour estimer coefficient de corrélation utilisé coefficient de corrélation de l'échantillonr ( il est également désigné comme Rxy ou r xy) :

où S x – écart typeéchantillons variable aléatoire x, calculé par la formule :

Comme le montre la formule de calcul corrélations, le dénominateur (produit des écarts types) normalise simplement le numérateur tel que corrélation s'avère être un nombre sans dimension de -1 à 1. Corrélation Et covariance fournir les mêmes informations (si elles sont connues écarts types ), Mais corrélation plus pratique à utiliser, car c'est une quantité sans dimension.
Calculer coefficient de corrélation Et covariance de l'échantillon dans MS EXCEL, ce n'est pas difficile, car il existe des fonctions spéciales CORREL() et KOVAR() à cet effet. Il est beaucoup plus difficile de comprendre comment interpréter les valeurs obtenues ; la majeure partie de l'article y est consacrée.
Retraite théorique
Rappelons que connexion de corrélation s'appelle une relation statistique consistant dans le fait que différentes significations une variable correspond à différentes moyenne les valeurs sont différentes (avec un changement de la valeur de X valeur moyenne Y change de façon régulière). On suppose que les deux les variables X et Y sont aléatoire valeurs et avoir une certaine dispersion aléatoire par rapport à elles valeur moyenne.
Note. Si une seule variable, par exemple Y, a un caractère aléatoire et que les valeurs de l'autre sont déterministes (fixées par le chercheur), alors on ne peut parler que de régression.
Ainsi, par exemple, lorsqu’on étudie la dépendance température annuelle moyenne tu ne peux pas en parler corrélations température et année d'observation et, en conséquence, appliquer des indicateurs corrélations avec leur interprétation correspondante.
Corrélation entre variables peut survenir de plusieurs manières :
- La présence d'une relation causale entre les variables. Par exemple, le montant des investissements dans la recherche scientifique (variable X) et le nombre de brevets reçus (Y). La première variable apparaît comme variable indépendante (facteur), deuxième - variable dépendante (résultat). Il faut se rappeler que la dépendance des quantités détermine la présence d'une corrélation entre elles, mais pas l'inverse.
- La présence de conjugaison (cause commune). Par exemple, à mesure que l'organisation se développe, le fonds salarial (masse salariale) et le coût de location des locaux augmentent. Il est évidemment faux de supposer que la location des locaux dépend de la masse salariale. Ces deux variables dépendent dans de nombreux cas de manière linéaire du nombre d’employés.
- Influence mutuelle des variables (quand l'une change, la deuxième variable change, et vice versa). Avec cette approche, deux formulations du problème sont autorisées ; Toute variable peut agir à la fois comme variable indépendante et comme variable dépendante.
Ainsi, indicateur de corrélation montre à quel point relation linéaire entre deux facteurs (s'il y en a un), et la régression vous permet de prédire un facteur en fonction de l'autre.
Corrélation, comme tout autre indicateur statistique, peut être utile lorsqu’il est utilisé correctement, mais son utilisation présente également des limites. S'il montre une relation linéaire clairement définie ou absence totale relations, alors corrélation reflétera cela à merveille. Mais, si les données montrent une relation non linéaire (par exemple quadratique), la présence de groupes de valeurs distincts ou de valeurs aberrantes, alors la valeur calculée coefficient de corrélation peut être trompeur (voir fichier exemple).
Corrélation proche de 1 ou -1 (c'est-à-dire proche en valeur absolue de 1) montre une forte relation linéaire entre les variables, une valeur proche de 0 ne montre aucune relation. Positif corrélation signifie qu'avec une augmentation d'un indicateur, l'autre augmente en moyenne, et avec un indicateur négatif, il diminue.
Pour calculer le coefficient de corrélation, il faut que les variables comparées satisfassent aux conditions suivantes :
- le nombre de variables doit être égal à deux ;
- les variables doivent être quantitatives (par exemple fréquence, poids, prix). La moyenne calculée de ces variables a une signification claire : prix moyen ou poids moyen patient. Contrairement aux variables quantitatives, les variables qualitatives (nominales) prennent des valeurs uniquement à partir d'un ensemble fini de catégories (par exemple, le sexe ou le groupe sanguin). Ces valeurs sont classiquement associées à des valeurs numériques (par exemple, le sexe féminin est 1 et le sexe masculin est 2). Il est clair que dans ce cas le calcul valeur moyenne, qui est nécessaire pour trouver corrélations, est incorrect, et donc le calcul lui-même est incorrect corrélations;
- les variables doivent être des variables aléatoires et avoir .
Les données bidimensionnelles peuvent avoir des structures différentes. Certains d’entre eux nécessitent certaines approches pour travailler :
- Pour les données avec une relation non linéaire corrélation doit être utilisé avec prudence. Pour certains problèmes, il peut être utile de transformer une ou les deux variables pour produire une relation linéaire (cela nécessite de faire une hypothèse sur le type de relation non linéaire afin de suggérer le type de transformation nécessaire).
- En utilisant nuages de points Certaines données peuvent présenter des variations inégales (dispersion). Le problème des variations inégales est que les emplacements présentant des variations élevées fournissent non seulement les informations les moins précises, mais ont également le plus grand impact lors du calcul des statistiques. Ce problème est également souvent résolu en transformant les données, par exemple en utilisant des logarithmes.
- On peut observer que certaines données sont divisées en groupes (clustering), ce qui peut indiquer la nécessité de diviser la population en parties.
- Une valeur aberrante (une valeur fortement déviante) peut fausser la valeur calculée du coefficient de corrélation. Une valeur aberrante peut être due au hasard, à une erreur dans la collecte des données ou peut en réalité refléter une caractéristique de la relation. Étant donné que la valeur aberrante s'écarte considérablement de la valeur moyenne, elle contribue largement au calcul de l'indicateur. Les indicateurs statistiques sont souvent calculés avec et sans prise en compte des valeurs aberrantes.
Utiliser MS EXCEL pour calculer la corrélation
Prenons 2 variables comme exemple X Et Oui et, en conséquence, échantillon composé de plusieurs paires de valeurs (X i ; Y i). Pour plus de clarté, construisons .
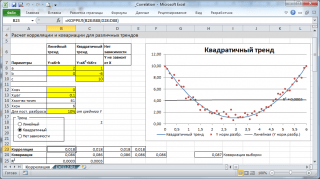
Note: Pour plus d'informations sur la création de diagrammes, consultez l'article. Dans le fichier d'exemple pour la construction nuages de points utilisé parce que ici nous nous sommes écartés de l'exigence selon laquelle la variable X doit être aléatoire (cela simplifie la génération différents types relations : construction de tendances et d’un spread donné). Pour les données réelles, vous devez utiliser un diagramme à nuages de points (voir ci-dessous).
Calculs corrélations nous mènerons pour divers cas relations entre variables : linéaire, quadratique et à manque de communication.
Note: Dans le fichier d'exemple, vous pouvez définir les paramètres de la tendance linéaire (pente, ordonnée à l'origine) et le degré de dispersion par rapport à cette ligne de tendance. Vous pouvez également ajuster les paramètres quadratiques.
Dans le fichier d'exemple pour la construction nuages de points s'il n'y a pas de dépendance des variables, un diagramme de dispersion est utilisé. Dans ce cas, les points du diagramme sont disposés sous la forme d'un nuage.

Note: Veuillez noter qu'en changeant l'échelle du diagramme le long de l'axe vertical ou horizontal, le nuage de points peut prendre l'apparence d'un diagramme vertical ou horizontal. ligne horizontale. Il est clair que les variables resteront indépendantes.
Comme mentionné ci-dessus, pour calculer coefficient de corrélation dans MS EXCEL, il existe une fonction CORREL(). Vous pouvez également utiliser la fonction similaire PEARSON(), qui renvoie le même résultat.
Pour être sûr que les calculs corrélations sont produits par la fonction CORREL() en utilisant les formules ci-dessus ; le fichier d'exemple montre le calcul ; corrélations en utilisant des formules plus détaillées :
=COVARIANCE.G(B28:B88;D28:D88)/STDEV.G(B28:B88)/STDEV.G(D28:D88)
=COVARIANCE.B(B28:B88;D28:D88)/STDEV.B(B28:B88)/STDEV.B(D28:D88)
Note: Carré coefficient de corrélation r est égal à coefficient de détermination R2, qui est calculé lors de la construction d'une droite de régression à l'aide de la fonction QPIRSON(). La valeur de R2 peut également être sortie vers diagramme de dispersion en créant une tendance linéaire à l'aide de la fonctionnalité standard MS EXCEL (sélectionnez le graphique, sélectionnez l'onglet Mise en page, puis dans le groupe Analyse cliquez sur le bouton Ligne de tendance et sélectionnez approximation linéaire). Pour plus d'informations sur la création d'une ligne de tendance, voir, par exemple, .
Utiliser MS EXCEL pour calculer la covariance
Covariance a un sens proche de (également une mesure de dispersion) à la différence qu'il est défini pour 2 variables, et dispersion- pour un. Par conséquent, cov(x;x)=VAR(x).

Pour calculer la covariance dans MS EXCEL (à partir de la version 2010), les fonctions COVARIATION.G() et COVARIATION.B() sont utilisées. Dans le premier cas, la formule de calcul est similaire à celle ci-dessus (fin .G représente Population), dans la seconde, au lieu du multiplicateur 1/n, on utilise 1/(n-1), c'est-à-dire fin .DANS représente Échantillon.
Note: La fonction COVAR(), présente dans MS EXCEL dans les versions antérieures, est similaire à la fonction COVARIATION.G().
Note: Les fonctions CORREL() et COVAR() sont présentées dans la version anglaise comme CORREL et COVAR. Les fonctions COVARIANCE.G() et COVARIANCE.B() comme COVARIANCE.P et COVARIANCE.S.
Formules supplémentaires pour le calcul covariances:
=SOMMEPRODUIT(B28:B88-MOYENNE(B28:B88);(D28:D88-MOYENNE(D28:D88)))/COUNT(D28:D88)
=SOMMEPRODUIT(B28:B88-MOYENNE(B28:B88),(D28:D88))/COMPTE(D28:D88)
=SOMMEPRODUIT(B28:B88;D28:D88)/COMTE(D28:D88)-MOYENNE(B28:B88)*MOYENNE(D28:D88)
Ces formules utilisent la propriété covariances:

Si les variables x Et oui indépendantes, alors leur covariance est égale à 0. Si les variables ne sont pas indépendantes, alors la variance de leur somme est égale à :
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
UN dispersion leur différence est égale
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Estimation de la signification statistique du coefficient de corrélation
Afin de tester l'hypothèse, nous devons connaître la distribution de la variable aléatoire, c'est-à-dire coefficient de corrélation r. Habituellement, l'hypothèse n'est pas testée pour r, mais pour la variable aléatoire t r :

qui a n-2 degrés de liberté.
Si la valeur calculée de la variable aléatoire |t r | est supérieure à la valeur critique t α,n-2 (α-spécifiée), alors l'hypothèse nulle est rejetée (la relation entre les valeurs est statistiquement significative).

Module complémentaire du package d'analyse
B pour calculer la covariance et la corrélation il y a des instruments du même nom analyse.

Après avoir appelé l'outil, une boîte de dialogue apparaît contenant les champs suivants :

- Intervalle de saisie: vous devez saisir un lien vers une plage avec des données sources pour 2 variables
- Regroupement: En règle générale, les données sources sont saisies dans 2 colonnes
- Libellés sur la première ligne: si la case est cochée, alors Intervalle de saisie doit contenir des en-têtes de colonnes. Il est recommandé de cocher la case pour que le résultat du Add-in contienne des colonnes informatives
- Intervalle de sortie: la plage de cellules où seront placés les résultats du calcul. Il suffit d'indiquer la cellule supérieure gauche de cette plage.
Le complément renvoie les valeurs calculées de corrélation et de covariance (pour la covariance, les variances des deux variables aléatoires sont également calculées).

Tâche:
Il existe un échantillon connexe de 26 paires de valeurs (x k,y k) :
| k | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| xk | 25.20000 | 26.40000 | 26.00000 | 25.80000 | 24.90000 | 25.70000 | 25.70000 | 25.70000 | 26.10000 | 25.80000 |
| ouais | 30.80000 | 29.40000 | 30.20000 | 30.50000 | 31.40000 | 30.30000 | 30.40000 | 30.50000 | 29.90000 | 30.40000 |
| k | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| xk | 25.90000 | 26.20000 | 25.60000 | 25.40000 | 26.60000 | 26.20000 | 26.00000 | 22.10000 | 25.90000 | 25.80000 |
| ouais | 30.30000 | 30.50000 | 30.60000 | 31.00000 | 29.60000 | 30.40000 | 30.70000 | 31.60000 | 30.50000 | 30.60000 |
| k | 21 | 22 | 23 | 24 | 25 | 26 |
| xk | 25.90000 | 26.30000 | 26.10000 | 26.00000 | 26.40000 | 25.80000 |
| ouais | 30.70000 | 30.10000 | 30.60000 | 30.50000 | 30.70000 | 30.80000 |
Nécessaire pour calculer/tracer :
- coefficient de corrélation ;
- tester l'hypothèse de dépendance des variables aléatoires X et Y, au niveau de signification α = 0,05 ;
- coefficients d'équation de régression linéaire ;
- diagramme de dispersion (champ de corrélation) et graphique linéaire de régression ;
SOLUTION:
1. Calculez le coefficient de corrélation.
Le coefficient de corrélation est un indicateur de l'influence probabiliste mutuelle de deux variables aléatoires. Coefficient de corrélation R. -1 peut prendre des valeurs de +1 à 1 . Si la valeur absolue est plus proche de 0 , alors cela témoigne d'un lien fort entre les quantités, et si plus proche de Coefficient de corrélation- alors cela indique une connexion faible ou son absence. Si valeur absolue
est égal à un, alors nous pouvons parler d'un lien fonctionnel entre les quantités, c'est-à-dire qu'une quantité peut être exprimée par une autre à l'aide d'une fonction mathématique.
| Le coefficient de corrélation peut être calculé à l'aide des formules suivantes : |
| Σ |
| n |
| σ y 2 | = |
|
| Mx | xk, | = | Mon
y k 2 - M y 2 (1.6) En pratique, la formule (1.4) est plus souvent utilisée pour calculer le coefficient de corrélation car cela nécessite moins de calculs. Cependant, si la covariance a été calculée précédemment cov(X,Y) , alors il est plus rentable d'utiliser la formule (1.1), car En plus de la valeur de covariance elle-même, vous pouvez également utiliser les résultats de calculs intermédiaires. 1.1 Calculons le coefficient de corrélation à l'aide de la formule (1.4) , pour ce faire, nous calculons les valeurs de x k 2, y k 2 et x k y k et les inscrivons dans le tableau 1.
xk. 1.2.1. xk 1.2. Calculons M x en utilisant la formule (1.5) 1.2.2. 669.50000 / 26 = 25.75000 x 1 + x 2 + … + x 26 = 25,20000 + 26,40000 + ... + 25,80000 = 669,500000 Mx = 25,750000. 1.3.1. 1.3. Calculons M y de la même manière ouais Ajoutons tous les éléments séquentiellement 1.3.2. y 1 + y 2 + … + y 26 = 30,80000 + 29,40000 + ... + 30,80000 = 793,000000 793.00000 / 26 = 30.50000 Divisez la somme obtenue par le nombre d'éléments de l'échantillon M y = 30,500000. 1.4.1. 1.4. De la même manière, nous calculons M xy 776.16000 + 776.16000 + ... + 794.64000 = 20412.830000 1.4.2. Ajoutons séquentiellement tous les éléments de la 6ème colonne du tableau 1 20412.83000 / 26 = 785.10885 Divisez la somme obtenue par le nombre d'éléments Mxy = 785,108846. 1.5.1. 1.5. Calculons la valeur de S x 2 à l'aide de la formule (1.6.) 635.04000 + 696.96000 + ... + 665.64000 = 17256.910000 1.5.2. Ajoutons séquentiellement tous les éléments de la 6ème colonne du tableau 1 17256.91000 / 26 = 663.72731 1.5.3. Ajoutons séquentiellement tous les éléments de la 4ème colonne du tableau 1 Soustrayez le carré de M x du dernier nombre pour obtenir la valeur de S x 2 = 663.72731 - 25.75000 2 = 663.72731 - 663.06250 = 0.66481 S x 2. 1.6.1. Ajoutons séquentiellement tous les éléments de la 5ème colonne du tableau 1 948.64000 + 864.36000 + ... + 948.64000 = 24191.840000 1.6.2. Ajoutons séquentiellement tous les éléments de la 6ème colonne du tableau 1 24191.84000 / 26 = 930.45538 1.6.3. Soustrayez le carré de M y du dernier nombre pour obtenir la valeur de S y 2 Sy 2 = 930.45538 - 30.50000 2 = 930.45538 - 930.25000 = 0.20538 1.7. Calculons le produit des quantités S x 2 et S y 2. S x 2 S y 2 = 0,66481 0,20538 = 0,136541 1.8. Prenons la racine carrée du dernier nombre et obtenons la valeur S x S y. S x S y = 0,36951 1.9. Calculons la valeur du coefficient de corrélation à l'aide de la formule (1.4.). R = (785,10885 - 25,75000 30,50000) / 0,36951 = (785,10885 - 785,37500) / 0,36951 = -0,72028 RÉPONSE : Rx,y = -0,720279 2. On vérifie la significativité du coefficient de corrélation (on vérifie l'hypothèse de dépendance).Étant donné que l’estimation du coefficient de corrélation est calculée sur un échantillon fini et peut donc s’écarter de sa valeur de population, il est nécessaire de tester la signification du coefficient de corrélation. La vérification est effectuée à l'aide du test t :
Variable aléatoire t suit la distribution t de Student et à l'aide du tableau de distribution t, il est nécessaire de trouver la valeur critique du critère (t cr.α) à un niveau de signification α donné. Si t calculé par la formule (2.1) en valeur absolue s'avère inférieur à t cr.α , alors il n'y a aucune dépendance entre les variables aléatoires X et Y. Sinon, les données expérimentales ne contredisent pas l'hypothèse de dépendance à l'égard de variables aléatoires. 2.1. Calculons la valeur du critère t à l'aide de la formule (2.1) et obtenons :
2.2. À l'aide du tableau de distribution t, nous déterminons la valeur critique du paramètre t cr.α La valeur souhaitée de tcr.α se situe à l'intersection de la ligne correspondant au nombre de degrés de liberté et de la colonne correspondant au niveau de signification α donné. Tableau 2 distribution t
2.2. Comparons la valeur absolue du critère t et t cr.α La valeur absolue du critère t n'est pas inférieure à la valeur critique t = 5,08680, t cr.α = 2,064, donc données expérimentales, avec probabilité 0,95(1 - α), ne contredit pas l'hypothèse sur la dépendance des variables aléatoires X et Y. 3. Calculez les coefficients de l'équation de régression linéaire.Une équation de régression linéaire est une équation d'une ligne droite qui se rapproche (décrit approximativement) la relation entre les variables aléatoires X et Y. Si nous supposons que la valeur X est libre et que Y dépend de X, alors l'équation de régression s'écrira sous la forme suit Y = a + b X (3.1), où :
Le coefficient calculé selon la formule (3.2) b appelé coefficient de régression linéaire. Dans certaines sources un est appelé coefficient de régression constant et b selon les variables. Les erreurs de prédiction de Y pour une valeur donnée X sont calculées à l'aide des formules : La quantité σ y/x (formule 3.4) est aussi appelée écart type résiduel, il caractérise l'écart de la valeur Y par rapport à la droite de régression décrite par l'équation (3.1) pour une valeur fixe (donnée) de X. | . |
S y / S x = 0,55582
3.3 Calculons le coefficient b selon la formule (3.2)
b = -0.72028 0.55582 = -0.40035
3.4 Calculons le coefficient a selon la formule (3.3)
un = 30.50000 - (-0.40035 25.75000) = 40.80894
3.5 Estimons les erreurs de l'équation de régression.
3.5.1 En prenant la racine carrée de S y 2 on obtient :
3.5.4 Calculons l'erreur relative en utilisant la formule (3.5)
δ y/x = (0,31437 / 30,50000)100 % = 1,03073 %
4. Nous construisons un diagramme de dispersion (champ de corrélation) et un graphique linéaire de régression.
Un nuage de points est une représentation graphique de paires correspondantes (x k, y k) sous forme de points sur un plan, en coordonnées rectangulaires avec les axes X et Y. Le champ de corrélation est l'une des représentations graphiques d'un échantillon associé (paire). Le graphique linéaire de régression est également tracé dans le même système de coordonnées.4.1. Les échelles et les points de départ sur les axes doivent être choisis avec soin pour garantir que le diagramme soit aussi clair que possible.
4.2. Trouvez l'élément minimum et maximum de l'échantillon X est respectivement le 18ème et le 15ème élément, x min = 22,10000 et x max = 26,60000.
4.3. Nous trouvons que l'élément minimum et maximum de l'échantillon Y sont respectivement les 2ème et 18ème éléments, y min = 29,40000 et y max = 31,60000.
4.4. Sur l'axe des x, sélectionnez un point de départ légèrement à gauche du point x 18 = 22,10000, et une échelle telle que le point x 15 = 26,60000 s'adapte sur l'axe et que les points restants soient clairement visibles.
4.5. Sur l'axe des ordonnées, sélectionnez un point de départ légèrement à gauche du point y 2 = 29,40000, et une échelle telle que le point y 18 = 31,60000 s'adapte sur l'axe et que les points restants soient clairement distinguables.
4.6. On place les valeurs x k sur l'axe des abscisses, et les valeurs y k sur l'axe des ordonnées.
4.7. Nous traçons les points (x 1, y 1), (x 2, y 2),…, (x 26, y 26) sur le plan de coordonnées. Nous obtenons le diagramme de dispersion (champ de corrélation) présenté dans la figure ci-dessous.
Traçons une ligne de régression. Pour ce faire, nous trouverons deux dont les coordonnées (x r1, y r1) et (x r2, y r2) satisfont à l'équation (3.6), tracez-les sur le plan de coordonnées et tracez une ligne droite à travers eux. Comme abscisse du premier point, on prend la valeur x min = 22,10000. En substituant la valeur x min dans l'équation (3.6), on obtient l'ordonnée du premier point. Ainsi, nous avons un point de coordonnées (22.10000, 31.96127). De la même manière, on obtient les coordonnées du deuxième point en mettant en abscisse la valeur x max = 26,60000.
Le deuxième point sera : (26.60000, 30.15970).
La droite de régression est représentée dans la figure ci-dessous en rouge
Veuillez noter que la droite de régression passe toujours par le point des valeurs moyennes de X et Y, c'est-à-dire avec des coordonnées (M x , M y). DANS recherche scientifique
Il est souvent nécessaire de trouver un lien entre les variables de résultat et les variables factorielles (le rendement d'une culture et la quantité de précipitations, la taille et le poids d'une personne dans des groupes homogènes par sexe et par âge, la fréquence cardiaque et la température corporelle, etc.) .
Les seconds sont des signes qui contribuent aux changements de ceux qui leur sont associés (les premiers).
Le concept d'analyse de corrélation
Il existe de nombreux Sur la base de ce qui précède, nous pouvons dire que l'analyse de corrélation est une méthode utilisée pour tester l'hypothèse sur la signification statistique de deux ou plusieurs variables si le chercheur peut les mesurer, mais pas les modifier.
Il existe d'autres définitions du concept en question. L'analyse de corrélation est une méthode de traitement qui consiste à étudier les coefficients de corrélation entre variables. Dans ce cas, les coefficients de corrélation entre une ou plusieurs paires de caractéristiques sont comparés pour établir des relations statistiques entre elles. L'analyse de corrélation est une méthode d'étude de la dépendance statistique entre des variables aléatoires avec la présence éventuelle d'une nature fonctionnelle stricte, dans laquelle la dynamique d'une variable aléatoire conduit à la dynamique de l'attente mathématique d'une autre.
Le concept de fausse corrélation Lors de la conduite analyse de corrélation
il faut tenir compte du fait qu'elle peut être réalisée par rapport à n'importe quel ensemble de caractéristiques, souvent absurdes les unes par rapport aux autres. Parfois, ils n’ont aucun lien de causalité entre eux.
Dans ce cas, on parle d’une fausse corrélation.
Problèmes d'analyse de corrélation
L'analyse de corrélation consiste à déterminer la relation entre les caractéristiques étudiées, et donc les tâches d'analyse de corrélation peuvent être complétées par les éléments suivants :
- identification des facteurs qui ont la plus grande influence sur la caractéristique résultante ;
- identifier les causes de connexions jusqu'alors inexplorées ;
- construction d'un modèle de corrélation avec son analyse paramétrique ;
- étude de l'importance des paramètres de communication et de leur évaluation d'intervalle.
Relation entre l'analyse de corrélation et la régression
La méthode d'analyse de corrélation ne se limite souvent pas à trouver l'étroitesse de la relation entre les grandeurs étudiées. Parfois, elle est complétée par la compilation d'équations de régression, qui sont obtenues à l'aide de l'analyse du même nom, et qui représentent une description de la dépendance de corrélation entre la ou les caractéristiques résultantes et le facteur (facteur). Cette méthode, avec l'analyse considérée, constitue la méthode
Conditions d'utilisation de la méthode
Les facteurs efficaces dépendent d’un ou plusieurs facteurs. La méthode d’analyse de corrélation peut être utilisée s’il existe grand nombre des observations sur la valeur des indicateurs efficaces et factoriels (facteurs), tandis que les facteurs étudiés doivent être quantitatifs et reflétés dans des sources spécifiques. Le premier peut être déterminé par la loi normale - dans ce cas, le résultat de l'analyse de corrélation est les coefficients de corrélation de Pearson, ou, si les caractéristiques n'obéissent pas à cette loi, le coefficient de corrélation de rang de Spearman est utilisé.

Règles de sélection des facteurs d'analyse de corrélation
Lors de l'application de cette méthode, il est nécessaire de déterminer les facteurs qui influencent les indicateurs de performance. Ils sont sélectionnés en tenant compte du fait qu'il doit y avoir des relations de cause à effet entre les indicateurs. Dans le cas de la création d'un modèle de corrélation multifactorielle, ceux qui ont un impact significatif sur l'indicateur résultant sont sélectionnés, alors qu'il est préférable de ne pas inclure de facteurs interdépendants avec un coefficient de corrélation par paire supérieur à 0,85 dans le modèle de corrélation, ainsi que ceux pour lequel la relation avec le paramètre résultant n'est pas de caractère linéaire ou fonctionnel.
Affichage des résultats
Les résultats de l'analyse de corrélation peuvent être présentés sous forme de texte et de graphiques. Dans le premier cas, ils sont présentés sous forme de coefficient de corrélation, dans le second, sous la forme d'un diagramme de dispersion.

En l'absence de corrélation entre les paramètres, les points du diagramme sont situés de manière chaotique, le degré moyen de connexion est caractérisé par un plus grand degré d'ordre et se caractérise par une distance plus ou moins uniforme des marques marquées par rapport à la médiane. Une connexion forte a tendance à être droite et à r = 1, le tracé de points est une ligne plate. La corrélation inverse diffère dans la direction du graphique du coin supérieur gauche au coin inférieur droit, la corrélation directe - du coin inférieur gauche au coin supérieur droit.
Représentation 3D d'un nuage de points
En plus de l'affichage traditionnel des nuages de points 2D, une représentation graphique 3D de l'analyse de corrélation est désormais utilisée.

Une matrice de nuages de points est également utilisée, qui affiche tous les tracés appariés sur une seule figure dans un format matriciel. Pour n variables, la matrice contient n lignes et n colonnes. Le graphique situé à l'intersection de la i-ème ligne et de la j-ème colonne est un tracé des variables Xi en fonction de Xj. Ainsi, chaque ligne et colonne est à une dimension, une seule cellule affiche un nuage de points à deux dimensions.

Évaluation de l'étanchéité de la connexion
L'étroitesse de la connexion de corrélation est déterminée par le coefficient de corrélation (r) : fort - r = ±0,7 à ±1, moyen - r = ±0,3 à ±0,699, faible - r = 0 à ±0,299. Cette classification n'est pas stricte. La figure montre un diagramme légèrement différent.

Un exemple d'utilisation de la méthode d'analyse de corrélation
Au Royaume-Uni, on a tenté recherche intéressante. Elle est consacrée au lien entre le tabagisme et le cancer du poumon et a été réalisée par analyse de corrélation. Cette observation est présentée ci-dessous.
Groupe professionnel | mortalité |
|
Agriculteurs, forestiers et pêcheurs | ||
Mineurs et carrières | ||
Fabricants de gaz, de coke et de produits chimiques | ||
Fabricants de verre et de céramique | ||
Ouvriers des fourneaux, forges, fonderies et laminoirs | ||
Ouvriers en électricité et électronique | ||
Ingénierie et métiers apparentés | ||
Industrie du bois | ||
Travailleurs du cuir | ||
Ouvriers du textile | ||
Fabricants de vêtements de travail | ||
Travailleurs des industries de l'alimentation, des boissons et du tabac | ||
Fabricants de papier et d'impression | ||
Fabricants d'autres produits | ||
Constructeurs | ||
Peintres et décorateurs | ||
Conducteurs de moteurs stationnaires, de grues, etc. | ||
Travailleurs non inclus ailleurs | ||
Travailleurs des transports et des communications | ||
Employés d'entrepôt, magasiniers, emballeurs et ouvriers de machines de remplissage | ||
Employés de bureau | ||
Vendeurs | ||
Travailleurs des sports et des loisirs | ||
Administrateurs et gestionnaires | ||
Professionnels, techniciens et artistes |
Nous commençons l'analyse de corrélation. Pour plus de clarté, il est préférable de commencer la solution par une méthode graphique, pour laquelle nous construirons un diagramme de dispersion.

Cela démontre une connexion directe. Cependant, il est difficile de tirer une conclusion sans ambiguïté en se basant uniquement sur la méthode graphique. Par conséquent, nous continuerons à effectuer une analyse de corrélation. Un exemple de calcul du coefficient de corrélation est présenté ci-dessous.
À l'aide d'un logiciel (MS Excel sera décrit ci-dessous à titre d'exemple), nous déterminons le coefficient de corrélation, qui est de 0,716, ce qui signifie un lien fort entre les paramètres étudiés. Déterminons la fiabilité statistique de la valeur obtenue à l'aide du tableau correspondant, pour lequel nous devons soustraire 2 à 25 paires de valeurs, nous obtenons ainsi 23 et en utilisant cette ligne du tableau nous trouvons r critique pour p = 0,01 (puisque ce sont des données médicales, une dépendance plus stricte, dans les autres cas p=0,05 suffit), soit 0,51 pour cette analyse de corrélation. L'exemple a démontré que le r calculé est supérieur au r critique et que la valeur du coefficient de corrélation est considérée comme statistiquement fiable.
Utiliser un logiciel lors de la réalisation d'une analyse de corrélation
Le type de traitement de données statistiques décrit peut être effectué à l'aide logiciel, en particulier MS Excel. La corrélation consiste à calculer les paramètres suivants à l'aide de fonctions :
1. Le coefficient de corrélation est déterminé à l'aide de la fonction CORREL (array1 ; array2). Tableau1,2 - cellule de l'intervalle de valeurs des variables résultantes et factorielles.
Le coefficient de corrélation linéaire est également appelé coefficient de corrélation de Pearson et, par conséquent, à partir d'Excel 2007, vous pouvez utiliser la fonction avec les mêmes tableaux.
L'affichage graphique de l'analyse de corrélation dans Excel se fait à l'aide du panneau « Graphiques » avec la sélection « Nuage de points ».
Après avoir spécifié les données initiales, nous obtenons un graphique.
2. Évaluer la signification du coefficient de corrélation par paire à l’aide du test t de Student. La valeur calculée du critère t est comparée à la valeur tabulée (critique) de cet indicateur à partir du tableau de valeurs correspondant du paramètre considéré, en tenant compte du niveau de signification spécifié et du nombre de degrés de liberté. Cette estimation est réalisée à l'aide de la fonction STUDISCOVER(probabilité ; degrés_de_liberté).
3. Matrice des coefficients de corrélation de paires. L'analyse est effectuée à l'aide de l'outil d'analyse des données, dans lequel la corrélation est sélectionnée. L'évaluation statistique des coefficients de corrélation de paires est effectuée en comparant sa valeur absolue avec la valeur tabulée (critique). Lorsque le coefficient de corrélation par paire calculé dépasse le coefficient critique, on peut dire, compte tenu du degré de probabilité donné, que l'hypothèse nulle sur la signification de la relation linéaire n'est pas rejetée.
En conclusion
L'utilisation de la méthode d'analyse de corrélation dans la recherche scientifique nous permet de déterminer la relation entre divers facteurs et indicateurs de performance. Il est nécessaire de prendre en compte qu'un coefficient de corrélation élevé peut être obtenu à partir d'une paire ou d'un ensemble de données absurdes et que ce type d'analyse doit donc être effectué sur un ensemble de données suffisamment large.
Après avoir obtenu la valeur calculée de r, il est conseillé de la comparer avec le r critique pour confirmer la fiabilité statistique d'une certaine valeur. L'analyse de corrélation peut être réalisée manuellement à l'aide de formules, ou à l'aide de logiciels, notamment MS Excel. Ici, vous pouvez également construire un diagramme de dispersion dans le but de représenter visuellement la relation entre les facteurs étudiés de l'analyse de corrélation et la caractéristique résultante.