Пример вычисления корреляции, построения линейной регрессии и проверки гипотезы зависимости двух СВ нашим сервисом. Корреляционно-регрессионный анализ в Excel: инструкция выполнения
В сегодняшней статье речь пойдет о том, как переменные могут быть связаны друг с другом. С помощью корреляции мы сможем определить, существует ли связь между первой и второй переменной. Надеюсь, это занятие покажется вам не менее увлекательным, чем предыдущие!
Корреляция измеряет мощность и направление связи между x и y. На рисунке представлены различные типы корреляции в виде графиков рассеяния упорядоченных пар (x, y). По традиции переменная х размещается на горизонтальной оси, а y - на вертикальной.

График А являет собой пример положительной линейной корреляции: при увеличении х также увеличивается у, причем линейно. График В показывает нам пример отрицательной линейной корреляции, на котором при увеличении х у линейно уменьшается. На графике С мы видим отсутствие корреляции между х и у. Эти переменные никоим образом не влияют друг на друга.
Наконец, график D - это пример нелинейных отношений между переменными. По мере увеличения х у сначала уменьшается, потом меняет направление и увеличивается.
Оставшаяся часть статьи посвящена линейным взаимосвязям между зависимой и независимой переменными.
Коэффициент корреляции
Коэффициент корреляции, r, предоставляет нам как силу, так и направление связи между независимой и зависимой переменными. Значения r находятся в диапазоне между — 1.0 и + 1.0. Когда r имеет положительное значение, связь между х и у является положительной (график A на рисунке), а когда значение r отрицательно, связь также отрицательна (график В). Коэффициент корреляции, близкий к нулевому значению, свидетельствует о том, что между х и у связи не существует график С).
Сила связи между х и у определяется близостью коэффициента корреляции к - 1.0 или +- 1.0. Изучите следующий рисунок.

График A показывает идеальную положительную корреляцию между х и у при r = + 1.0. График В - идеальная отрицательная корреляция между х и у при r = — 1.0. Графики С и D - примеры более слабых связей между зависимой и независимой переменными.
Коэффициент корреляции, r, определяет, как силу, так и направление связи между зависимой и независимой переменными. Значения r находятся в диапазоне от — 1.0 (сильная отрицательная связь) до + 1.0 (сильная положительная связь). При r= 0 между переменными х и у нет никакой связи.
Мы можем вычислить фактический коэффициент корреляции с помощью следующего уравнения:

Ну и ну! Я знаю, что выглядит это уравнение как страшное нагромождение непонятных символов, но прежде чем ударяться в панику, давайте применим к нему пример с экзаменационной оценкой. Допустим, я хочу определить, существует ли связь между количеством часов, посвященных студентом изучению статистики, и финальной экзаменационной оценкой. Таблица, представленная ниже, поможет нам разбить это уравнение на несколько несложных вычислений и сделать их более управляемыми.

![]()

Как видите, между числом часов, посвященных изучению предмета, и экзаменационной оценкой существует весьма сильная положительная корреляция. Преподаватели будут весьма рады узнать об этом.
Какова выгода устанавливать связь между подобными переменными? Отличный вопрос. Если обнаруживается, что связь существует, мы можем предугадать экзаменационные результаты на основе определенного количества часов, посвященных изучению предмета. Проще говоря, чем сильнее связь, тем точнее будет наше предсказание.
Использование Excel для вычисления коэффициентов корреляции
Я уверен, что, взглянув на эти ужасные вычисления коэффициентов корреляции, вы испытаете истинную радость, узнав, что программа Excel может выполнить за вас всю эту работу с помощью функции КОРРЕЛ со следующими характеристиками:
КОРРЕЛ (массив 1; массив 2),
массив 1 = диапазон данных для первой переменной,
массив 2 = диапазон данных для второй переменной.
Например, на рисунке показана функция КОРРЕЛ, используемая при вычислении коэффициента корреляции для примера с экзаменационной оценкой.

При корреляционной связи одной и той же величине одного признака соответствуют разные величины другого. Например: между ростом и весом имеется корреляционная связь, между заболеваемостью злокачественными новообразованиямии возрастом и т.д.
Существует 2 метода вычисления коэффициента корреляции: метод квадратов(Пирсона), метод рангов (Спирмена).
Наиболее точным является метод квадратов (Пирсона), при котором коэффициент корреляции определяется по формуле: , где
r ху ― коэффициент корреляции между статистическим рядом X и Y.
d х ― отклонение каждого из чисел статистического ряда X от своей средней арифметической.
d у ― отклонение каждого из чисел статистического ряда Y от своей средней арифметической.
В зависимости от силы связи и ее направления коэффициент корреляции может находиться в пределах от 0 до 1 (-1). Коэффициент корреляции, равный 0, говорит о полном отсутствии связи. Чем ближе уровень коэффициента корреляции к 1 или (-1), тем соответственно больше, теснее измеряемая им прямая или обратная связь. При коэффициенте корреляции равном 1 или (-1) связь полная, функциональная.
Схема оценки силы корреляционной связи по коэффициенту корреляции
|
Сила связи |
Величина коэффициента корреляции при наличии |
|
|
прямой связи (+) |
обратной связи (-) |
|
|
Связь отсутствует | ||
|
Связь малая (слабая) |
от 0 до +0,29 |
от 0 до –0,29 |
|
Связь средняя (умеренная) |
от +0,3 до +0,69 |
от –0,3 до –0,69 |
|
Связь большая (сильная) |
от +0,7 до +0,99 |
от –0,7 до –0,99 |
|
Связь полная (функциональная) | ||
Для вычисления коэффициента корреляции по методу квадратов составляется таблица из 7 колонок. Разберем процесс вычисления на примере:
ОПРЕДЕЛИТЬ СИЛУ И ХАРАКТЕР СВЯЗИ МЕЖДУ
|
Пора- ность зобом (V y ) |
d x = V x –M x |
d y = V y –M y |
d x d y |
d x 2 |
d y 2 |
|
|
Σ -1345 ,0 |
Σ 13996 ,0 |
Σ 313 , 47 |
1. Определяем среднее содержание йода в воде (в мг/л).
 мг/л
мг/л
2.Определяем среднюю пораженность зобом в %.

3. Определяем отклонение каждого V x от М x , т.е. d x .
201–138=63; 178–138=40 и т.д.
4. Аналогично определяем отклонение каждого V у от M у, т.е. d у.
0,2–3,8=-3,6; 0,6–38=-3,2 и т.д.
5. Определяем произведения отклонений. Полученное произведение суммируем и получаем.

6. d х возводим в квадрат и результаты суммируем, получаем.

7. Аналогично возводим в квадрат d у, результаты суммируем, получим

8. Наконец, все полученные суммы подставляем в формулу:

Для решения вопроса о достоверности коэффициента корреляции определяют его среднюю ошибку по формуле:

(Если число наблюдений менее 30, тогда в знаменателе n–1).
В нашем примере

Величина коэффициента корреляции считается достоверной, если не менее чем в 3 раза превышает свою среднюю ошибку.
В нашем примере

Таким образом, коэффициент корреляции не достоверен, что вызывает необходимость увеличения числа наблюдений.
Коэффициент корреляции можно определить несколько менее точным, но намного более легким способом ― методом рангов (Спирмена).
Метод Спирмена: P=1-(6∑d 2 /n-(n 2 -1))
составить два ряда из парных сопоставляемых признаков, обозначив первый и второй ряд соответственно х и у. При этом представить первый ряд признака в убывающем или возрастающем порядке, а числовые значения второго ряда расположить напротив тех значений первого ряда, которым они соответствуют
величину признака в каждом из сравниваемых рядов заменить порядковым номером (рангом). Рангами, или номерами, обозначают места показателей (значения) первого и второго рядов. При этом числовым значениям второго признака ранги должны присваиваться в том же порядке, какой был принят при раздаче их величинам первого признака. При одинаковых величинах признака в ряду ранги следует определять как среднее число из суммы порядковых номеров этих величин
определить разность рангов между х и у (d): d = х - у
возвести полученную разность рангов в квадрат (d 2)
получить сумму квадратов разности (Σ d 2) и подставить полученные значения в формулу:
Пример: методом рангов установить направление и силу связи между стажем работы в годах и частотой травм, если получены следующие данные:
Обоснование выбора метода: для решения задачи может быть выбран только метод ранговой корреляции, т.к. первый ряд признака "стаж работы в годах" имеет открытые варианты (стаж работы до 1 года и 7 и более лет), что не позволяет использовать для установления связи между сопоставляемыми признаками более точный метод - метод квадратов.
Решение . Последовательность расчетов изложена в тексте, результаты представлены в табл. 2.
Таблица 2
|
Стаж работы в годах |
Число травм |
Порядковые номера (ранги) |
Разность рангов |
Квадрат разности рангов |
|
|
d(х-у) |
d 2 |
||||
Каждый из рядов парных признаков обозначить через "х" и через "у" (графы 1-2).
Величину каждого из признаков заменить ранговым (порядковым) номером. Порядок раздачи рангов в ряду "x" следующий: минимальному значению признака (стаж до 1 года) присвоен порядковый номер "1", последующим вариантам этого же ряда признака соответственно в порядке увеличения 2-й, 3-й, 4-й и 5-й порядковые номера - ранги (см. графу 3). Аналогичный порядок соблюдается при раздаче рангов второму признаку "у" (графа 4). В тех случаях, когда встречаются несколько одинаковых по величине вариант (например, в задаче-эталоне это 12 и 12 травм на 100 работающих при стаже 3-4 года и 5-6 лет, порядковый номер обозначить средним числом из суммы их порядковых номеров. Эти данные о числе травм (12 травм) при ранжировании должны занимать 2 и 3 места, таким образом среднее число из них равно (2 + 3)/2 = 2,5. Таким образом, числу травм "12" и "12" (признаку) следует раздать ранговые номера одинаковые - "2,5" (графа 4).
Определить разность рангов d = (х - у) - (графа 5)
Разность рангов возвести в квадрат (d 2) и получить сумму квадратов разности рангов Σ d 2 (графа 6).
Произвести расчет коэффициента ранговой корреляции по формуле:
 где
n - число сопоставляемых пар вариант в
ряду "x" и в ряду "у"
где
n - число сопоставляемых пар вариант в
ряду "x" и в ряду "у"
Вычислим коэффициент корреляции и ковариацию для разных типов взаимосвязей случайных величин.
Коэффициент корреляции (критерий корреляции Пирсона, англ. Pearson Product Moment correlation coefficient) определяет степень линейной взаимосвязи между случайными величинами.
Как следует из определения, для вычисления коэффициента корреляции требуется знать распределение случайных величин Х и Y. Если распределения неизвестны, то для оценки коэффициента корреляции используется выборочный коэффициент корреляции r (еще он обозначается как R xy или r xy ) :

где S x – стандартное отклонение выборки случайной величины х, вычисляемое по формуле:

Как видно из формулы для расчета корреляции , знаменатель (произведение стандартных отклонений) просто нормирует числитель таким образом, что корреляция оказывается безразмерным числом от -1 до 1. Корреляция и ковариация предоставляют одну и туже информацию (если известны стандартные отклонения ), но корреляцией удобнее пользоваться, т.к. она является безразмерной величиной.
Рассчитать коэффициент корреляции и ковариацию выборки в MS EXCEL не представляет труда, так как для этого имеются специальные функции КОРРЕЛ() и КОВАР() . Гораздо сложнее разобраться, как интерпретировать полученные значения, большая часть статьи посвящена именно этому.
Теоретическое отступление
Напомним, что корреляционной связью называют статистическую связь, состоящую в том, что различным значениям одной переменной соответствуют различные средние значения другой (с изменением значения Х среднее значение Y изменяется закономерным образом). Предполагается, что обе переменные Х и Y являются случайными величинами и имеют некий случайный разброс относительно их среднего значения .
Примечание . Если случайную природу имеет только одна переменная, например, Y, а значения другой являются детерминированными (задаваемыми исследователем), то можно говорить только о регрессии.
Таким образом, например, при исследовании зависимости среднегодовой температуры нельзя говорить о корреляции температуры и года наблюдения и, соответственно, применять показатели корреляции с соответствующей их интерпретацией.
Корреляционная связь между переменными может возникнуть несколькими путями:
- Наличие причинной зависимости между переменными. Например, количество инвестиций в научные исследования (переменная Х) и количество полученных патентов (Y). Первая переменная выступает как независимая переменная (фактор) , вторая - зависимая переменная (результат) . Необходимо помнить, что зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
- Наличие сопряженности (общей причины). Например, с ростом организации растет фонд оплаты труда (ФОТ) и затраты на аренду помещений. Очевидно, что неправильно предполагать, что аренда помещений зависит от ФОТ. Обе этих переменных во многих случаях линейно зависят от количества персонала.
- Взаимовлияние переменных (при изменении одной, вторая переменная изменяется, и наоборот). При таком подходе допустимы две постановки задачи; любая переменная может выступать как в роли независимой переменной и в роли зависимой.
Таким образом, показатель корреляции показывает, насколько сильна линейная взаимосвязь между двумя факторами (если она есть), а регрессия позволяет прогнозировать один фактор на основе другого.
Корреляция , как и любой другой статистический показатель, при правильном применении может быть полезной, но она также имеет и ограничения по использованию. Если показывает четко выраженную линейную зависимость или полное отсутствие взаимосвязи, то корреляция замечательно это отразит. Но, если данные показывают нелинейную взаимосвязь (например, квадратичную), наличие отдельных групп значений или выбросов, то вычисленное значение коэффициента корреляции может ввести в заблуждение (см. файл примера ).
Корреляция близкая к 1 или -1 (т.е. близкая по модулю к 1) показывает сильную линейную взаимосвязь переменных, значение близкое к 0 показывает отсутствие взаимосвязи. Положительная корреляция означает, что с ростом одного показателя другой в среднем увеличивается, а при отрицательной – уменьшается.
Для вычисления коэффициента корреляции требуется, чтобы сопоставляемые переменные удовлетворяли следующим условиям:
- количество переменных должно быть равно двум;
- переменные должны быть количественными (например, частота, вес, цена). Вычисленное среднее значение этих переменных имеет понятный смысл: средняя цена или средний вес пациента. В отличие от количественных, качественные (номинальные) переменные принимают значения лишь из конечного набора категорий (например, пол или группа крови). Этим значениям условно сопоставлены числовые значения (например, женский пол – 1, а мужской – 2). Понятно, что в этом случае вычисление среднего значения , которое требуется для нахождения корреляции , некорректно, а значит некорректно и вычисление самой корреляции ;
- переменные должны быть случайными величинами и иметь .
Двумерные данные могут иметь различную структуру. Для работы с некоторыми из них требуются определенные подходы:
- Для данных с нелинейной связью корреляцию нужно использовать с осторожностью. Для некоторых задач бывает полезно преобразовать одну или обе переменных так, чтобы получить линейную взаимосвязь (для этого требуется сделать предположение о виде нелинейной связи, чтобы предложить нужный тип преобразования).
- С помощью диаграммы рассеяния у некоторых данных можно наблюдать неравную вариацию (разброс). Проблема неодинаковой вариации состоит в том, что места с высокой вариацией не только предоставляют наименее точную информацию, но и оказывают наибольшее влияние при расчете статистических показателей. Эту проблему также часто решают с помощью преобразования данных, например, с помощью логарифмирования.
- У некоторых данных можно наблюдать разделение на группы (clustering), что может свидетельствовать о необходимости разделения совокупности на части.
- Выброс (резко отклоняющееся значение) может исказить вычисленное значение коэффициента корреляции. Выброс может быть причиной случайности, ошибки при сборе данных или могут действительно отражать некую особенность взаимосвязи. Так как выброс сильно отклоняется от среднего значения, то он вносит большой вклад при расчете показателя. Часто расчет статистических показателей производят с и без учета выбросов.
Использование MS EXCEL для расчета корреляции
В качестве примера возьмем 2 переменные Х и Y и, соответственно, выборку состоящую из нескольких пар значений (Х i ; Y i). Для наглядности построим .
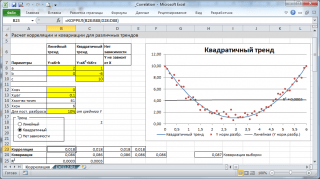
Примечание : Подробнее о построении диаграмм см. статью . В файле примера для построения диаграммы рассеяния использована , т.к. мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс). В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
Расчеты корреляции проведем для различных случаев взаимосвязи между переменными: линейной, квадратичной и при отсутствии связи .
Примечание : В файле примера можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В файле примера для построения диаграммы рассеяния в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.

Примечание : Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми.
Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ() . Также можно воспользоваться аналогичной функцией PEARSON() , которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления корреляции производятся функцией КОРРЕЛ() по вышеуказанным формулам, в файле примера приведено вычисление корреляции с помощью более подробных формул:
=КОВАРИАЦИЯ.Г(B28:B88;D28:D88)/СТАНДОТКЛОН.Г(B28:B88)/СТАНДОТКЛОН.Г(D28:D88)
=КОВАРИАЦИЯ.В(B28:B88;D28:D88)/СТАНДОТКЛОН.В(B28:B88)/СТАНДОТКЛОН.В(D28:D88)
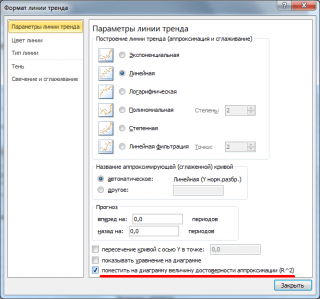
Примечание : Квадрат коэффициента корреляции r равен коэффициенту детерминации R2, который вычисляется при построении линии регрессии с помощью функции КВПИРСОН() . Значение R2 также можно вывести на диаграмме рассеяния , построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку Макет , затем в группе Анализ нажмите кнопку Линия тренда и выберите Линейное приближение ). Подробнее о построении линии тренда см., например, в .
Использование MS EXCEL для расчета ковариации
Ковариация близка по смыслу с (также является мерой разброса) с тем отличием, что она определена для 2-х переменных, а дисперсия - для одной. Поэтому, cov(x;x)=VAR(x).

Для вычисления ковариации в MS EXCEL (начиная с версии 2010 года) используются функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() . В первом случае формула для вычисления аналогична вышеуказанной (окончание .Г обозначает Генеральная совокупность ), во втором – вместо множителя 1/n используется 1/(n-1), т.е. окончание .В обозначает Выборка .
Примечание : Функция КОВАР() , которая присутствует в MS EXCEL более ранних версий, аналогична функции КОВАРИАЦИЯ.Г() .
Примечание : Функции КОРРЕЛ() и КОВАР() в английской версии представлены как CORREL и COVAR. Функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() как COVARIANCE.P и COVARIANCE.S.
Дополнительные формулы для расчета ковариации :
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88-СРЗНАЧ(D28:D88)))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88;D28:D88)/СЧЁТ(D28:D88)-СРЗНАЧ(B28:B88)*СРЗНАЧ(D28:D88)
Эти формулы используют свойство ковариации :

Если переменные x и y независимые, то их ковариация равна 0. Если переменные не являются независимыми, то дисперсия их суммы равна:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
А дисперсия их разности равна
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Оценка статистической значимости коэффициента корреляции
Для того чтобы проверить гипотезу, мы должны знать распределение случайной величины, т.е. коэффициента корреляции r. Обычно, проверку гипотезы осуществляют не для r, а для случайной величины t r:

которая имеет с n-2 степенями свободы.
Если вычисленное значение случайной величины |t r | больше, чем критическое значение t α,n-2 (α- заданный ), то нулевую гипотезу отклоняют (взаимосвязь величин является статистически значимой).

Надстройка Пакет анализа
В для вычисления ковариации и корреляции имеются одноименные инструменты анализа .

После вызова инструмента появляется диалоговое окно, которое содержит следующие поля:

- Входной интервал : нужно ввести ссылку на диапазон с исходными данными для 2-х переменных
- Группирование : как правило, исходные данные вводятся в 2 столбца
- Метки в первой строке : если установлена галочка, то Входной интервал должен содержать заголовки столбцов. Рекомендуется устанавливать галочку, чтобы результат работы Надстройки содержал информативные столбцы
- Выходной интервал : диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
Надстройка возвращает вычисленные значения корреляции и ковариации (для ковариации также вычисляются дисперсии обоих случайных величин).

Задача:
Имеется связанная выборка из 26 пар значений (х k
,y k
):
| k | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| x k | 25.20000 | 26.40000 | 26.00000 | 25.80000 | 24.90000 | 25.70000 | 25.70000 | 25.70000 | 26.10000 | 25.80000 |
| y k | 30.80000 | 29.40000 | 30.20000 | 30.50000 | 31.40000 | 30.30000 | 30.40000 | 30.50000 | 29.90000 | 30.40000 |
| k | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| x k | 25.90000 | 26.20000 | 25.60000 | 25.40000 | 26.60000 | 26.20000 | 26.00000 | 22.10000 | 25.90000 | 25.80000 |
| y k | 30.30000 | 30.50000 | 30.60000 | 31.00000 | 29.60000 | 30.40000 | 30.70000 | 31.60000 | 30.50000 | 30.60000 |
| k | 21 | 22 | 23 | 24 | 25 | 26 |
| x k | 25.90000 | 26.30000 | 26.10000 | 26.00000 | 26.40000 | 25.80000 |
| y k | 30.70000 | 30.10000 | 30.60000 | 30.50000 | 30.70000 | 30.80000 |
Требуется вычислить/построить:
- коэффициент корреляции;
- проверить гипотезу зависимости случайных величин X и Y, при уровне значимости α
= 0.05 ;
- коэффициенты уравнения линейной регрессии;
- диаграмму рассеяния (корреляционное поле) и график линии регрессии;
РЕШЕНИЕ:
1. Вычисляем коэффициент корреляции.
Коэффициент корреляции - это показатель взаимного вероятностного влияния двух случайных величин. Коэффициент корреляции R может принимать значения от -1 до +1 . Если абсолютное значение находится ближе к 1 , то это свидетельство сильной связи между величинами, а если ближе к 0 - то, это говорит о слабой связи или ее отсутствии. Если абсолютное значение R равно единице, то можно говорить о функциональной связи между величинами, то есть одну величину можно выразить через другую посредством математической функции.
Вычислить коэффициент корреляции можно по следующим формулам:
| n |
| Σ |
| k = 1 |
| M x | = |
|
| x k , | M y | = | или по формуле
На практике, для вычисления коэффициента корреляции чаще используется формула (1.4) т.к. она требует меньше вычислений. Однако если предварительно была вычислена ковариация cov(X,Y) , то выгоднее использовать формулу (1.1), т.к. кроме собственно значения ковариации можно воспользоваться и результатами промежуточных вычислений. 1.1 Вычислим коэффициент корреляции по формуле (1.4) , для этого вычислим значения x k 2 , y k 2 и x k y k и занесем их в таблицу 1. Таблица 1
1.2. Вычислим M x по формуле (1.5) . 1.2.1. x k x 1 + x 2 + … + x 26 = 25.20000 + 26.40000 + ... + 25.80000 = 669.500000 1.2.2. 669.50000 / 26 = 25.75000 M x = 25.750000 1.3. Аналогичным образом вычислим M y . 1.3.1. Сложим последовательно все элементы y k y 1 + y 2 + … + y 26 = 30.80000 + 29.40000 + ... + 30.80000 = 793.000000 1.3.2. Разделим полученную сумму на число элементов выборки 793.00000 / 26 = 30.50000 M y = 30.500000 1.4. Аналогичным образом вычислим M xy . 1.4.1. Сложим последовательно все элементы 6-го столбца таблицы 1 776.16000 + 776.16000 + ... + 794.64000 = 20412.830000 1.4.2. Разделим полученную сумму на число элементов 20412.83000 / 26 = 785.10885 M xy = 785.108846 1.5. Вычислим значение S x 2 по формуле (1.6.) . 1.5.1. Сложим последовательно все элементы 4-го столбца таблицы 1 635.04000 + 696.96000 + ... + 665.64000 = 17256.910000 1.5.2. Разделим полученную сумму на число элементов 17256.91000 / 26 = 663.72731 1.5.3. Вычтем из последнего числа квадрат величины M x получим значение для S x 2 S x 2 = 663.72731 - 25.75000 2 = 663.72731 - 663.06250 = 0.66481 1.6. Вычислим значение S y 2 по формуле (1.6.) . 1.6.1. Сложим последовательно все элементы 5-го столбца таблицы 1 948.64000 + 864.36000 + ... + 948.64000 = 24191.840000 1.6.2. Разделим полученную сумму на число элементов 24191.84000 / 26 = 930.45538 1.6.3. Вычтем из последнего числа квадрат величины M y получим значение для S y 2 S y 2 = 930.45538 - 30.50000 2 = 930.45538 - 930.25000 = 0.20538 1.7. Вычислим произведение величин S x 2 и S y 2 . S x 2 S y 2 = 0.66481 0.20538 = 0.136541 1.8. Извлечем и последнего числа квадратный корень, получим значение S x S y . S x S y = 0.36951 1.9. Вычислим значение коэффициента корреляции по формуле (1.4.) . R = (785.10885 - 25.75000 30.50000) / 0.36951 = (785.10885 - 785.37500) / 0.36951 = -0.72028 ОТВЕТ: R x,y = -0.720279 2. Проверяем значимость коэффициента корреляции (проверяем гипотезу зависимости).Поскольку оценка коэффициента корреляции вычислена на конечной выборке, и поэтому может отклоняться от своего генерального значения,
необходимо проверить значимость коэффициента корреляции. Проверка производится с помощью t
-критерия:
Случайная величина t следует t -распределению Стьюдента и по таблице t -распределения необходимо найти критическое значение критерия (t кр.α) при заданном уровне значимости α . Если вычисленное по формуле (2.1) t по модулю окажется меньше чем t кр.α , то зависимости между случайными величинами X и Y нет. В противном случае, экспериментальные данные не противоречат гипотезе о зависимости случайных величин. 2.1. Вычислим значение t -критерия по формуле (2.1) получим:
2.2. Определим по таблице t -распределения критическое значение параметра t кр.α Искомое значение t
кр.α располагается на пересечении строки соответствующей числу степеней свободы
и столбца соответствующего заданному уровню значимости α
. Таблица 2 t -распределение
2.2. Сравним абсолютное значение t -критерия и t кр.α Абсолютное значение t -критерия не меньше критического t = 5.08680, t кр.α = 2.064, следовательно экспериментальные данные, с вероятностью 0.95 (1 - α ), не противоречат гипотезе о зависимости случайных величин X и Y. 3. Вычисляем коэффициенты уравнения линейной регрессии.Уравнение линейной регрессии представляет собой уравнение прямой, аппроксимирующей (приблизительно описывающей) зависимость между случайными величинами X и Y. Если считать, что величина X свободная, а Y зависимая от Х, то уравнение регрессии запишется следующим образом Y = a + b X (3.1), где:
Рассчитанный по формуле (3.2) коэффициент b называют коэффициентом линейной регрессии. В некоторых источниках a называют постоянным коэффициентом регрессии и b соответственно переменным. Погрешности предсказания Y по заданному значению X вычисляются по формулам: Величину σ y/x (формула 3.4) еще называют остаточным средним квадратическим отклонением , оно характеризует уход величины Y от линии регрессии, описываемой уравнением (3.1), при фиксированном (заданном) значении X. | . |
S y / S x = 0.55582
3.3 Вычислим коэффициент b по формуле (3.2)
b = -0.72028 0.55582 = -0.40035
3.4 Вычислим коэффициент a по формуле (3.3)
a = 30.50000 - (-0.40035 25.75000) = 40.80894
3.5 Оценим погрешности уравнения регрессии .
3.5.1 Извлечем из S y 2 квадратный корень получим:
3.5.4 Вычислим относительную погрешность по формуле (3.5)
δ y/x = (0.31437 / 30.50000)100% = 1.03073%
4. Строим диаграмму рассеяния (корреляционное поле) и график линии регрессии.
Диаграмма рассеяния - это графическое изображение соответствующих пар (x k , y k ) в виде точек плоскости, в прямоугольных координатах с осями X и Y. Корреляционное поле является одним из графических представлений связанной (парной) выборки. В той же системе координат строится и график линии регрессии. Следует тщательно выбрать масштабы и начальные точки на осях, чтобы диаграмма была максимально наглядной.4.1. Находим минимальный и максимальный элемент выборки X это 18-й и 15-й элементы соответственно, x min = 22.10000 и x max = 26.60000.
4.2. Находим минимальный и максимальный элемент выборки Y это 2-й и 18-й элементы соответственно, y min = 29.40000 и y max = 31.60000.
4.3. На оси абсцисс выбираем начальную точку чуть левее точки x 18 = 22.10000, и такой масштаб, чтобы на оси поместилась точка x 15 = 26.60000 и отчетливо различались остальные точки.
4.4. На оси ординат выбираем начальную точку чуть левее точки y 2 = 29.40000, и такой масштаб, чтобы на оси поместилась точка y 18 = 31.60000 и отчетливо различались остальные точки.
4.5. На оси абсцисс размещаем значения x k , а на оси ординат значения y k .
4.6. Наносим точки (x 1 , y 1 ), (x 2 , y 2 ),…,(x 26 , y 26 ) на координатную плоскость. Получаем диаграмму рассеяния (корреляционное поле), изображенное на рисунке ниже.
4.7. Начертим линию регрессии.
Для этого найдем две различные точки с координатами (x r1 , y r1) и (x r2 , y r2) удовлетворяющие уравнению (3.6), нанесем их на координатную плоскость и проведем через них прямую. В качестве абсциссы первой точки возьмем значение x min = 22.10000. Подставим значение x min в уравнение (3.6), получим ординату первой точки. Таким образом имеем точку с координатами (22.10000, 31.96127). Аналогичным образом получим координаты второй точки, положив в качестве абсциссы значение x max = 26.60000. Вторая точка будет: (26.60000, 30.15970).
Линия регрессии показана на рисунке ниже красным цветом
Обратите внимание, что линия регрессии всегда проходит через точку средних значений величин Х и Y, т.е. с координатами (M x , M y).
В научных исследованиях часто возникает необходимость в нахождении связи между результативными и факторными переменными (урожайностью какой-либо культуры и количеством осадков, ростом и весом человека в однородных группах по полу и возрасту, частотой пульса и температурой тела и т.д.).
Вторые представляют собой признаки, способствующие изменению таковых, связанных с ними (первыми).
Понятие о корреляционном анализе
Существует множество Исходя из вышеизложенного, можно сказать, что корреляционный анализ — это метод, применяющийся с целью проверки гипотезы о статистической значимости двух и более переменных, если исследователь их может измерять, но не изменять.
Есть и другие определения рассматриваемого понятия. Корреляционный анализ — это метод обработки заключающийся в изучении коэффициентов корреляции между переменными. При этом сравниваются коэффициенты корреляции между одной парой или множеством пар признаков, для установления между ними статистических взаимосвязей. Корреляционный анализ — это метод по изучению статистической зависимости между случайными величинами с необязательным наличием строгого функционального характера, при которой динамика одной случайной величины приводит к динамике математического ожидания другой.
Понятие о ложности корреляции
При проведении корреляционного анализа необходимо учитывать, что его можно провести по отношению к любой совокупности признаков, зачастую абсурдных по отношению друг к другу. Порой они не имеют никакой причинной связи друг с другом.
В этом случае говорят о ложной корреляции.
Задачи корреляционного анализа
Исходя из приведенных выше определений, можно сформулировать следующие задачи описываемого метода: получить информацию об одной из искомых переменных с помощью другой; определить тесноту связи между исследуемыми переменными.
Корреляционный анализ предполагает определение зависимости между изучаемыми признаками, в связи с чем задачи корреляционного анализа можно дополнить следующими:
- выявление факторов, оказывающих наибольшее влияние на результативный признак;
- выявление неизученных ранее причин связей;
- построение корреляционной модели с ее параметрическим анализом;
- исследование значимости параметров связи и их интервальная оценка.
Связь корреляционного анализа с регрессионным
Метод корреляционного анализа часто не ограничивается нахождением тесноты связи между исследуемыми величинами. Иногда он дополняется составлением уравнений регрессии, которые получают с помощью одноименного анализа, и представляющих собой описание корреляционной зависимости между результирующим и факторным (факторными) признаком (признаками). Этот метод в совокупности с рассматриваемым анализом составляет метод
Условия использования метода
Результативные факторы зависят от одного до нескольких факторов. Метод корреляционного анализа может применяться в том случае, если имеется большое количество наблюдений о величине результативных и факторных показателей (факторов), при этом исследуемые факторы должны быть количественными и отражаться в конкретных источниках. Первое может определяться нормальным законом — в этом случае результатом корреляционного анализа выступают коэффициенты корреляции Пирсона, либо, в случае, если признаки не подчиняются этому закону, используется коэффициент ранговой корреляции Спирмена.

Правила отбора факторов корреляционного анализа
При применении данного метода необходимо определиться с факторами, оказывающими влияние на результативные показатели. Их отбирают с учетом того, что между показателями должны присутствовать причинно-следственные связи. В случае создания многофакторной корреляционной модели отбирают те из них, которые оказывают существенное влияние на результирующий показатель, при этом взаимозависимые факторы с коэффициентом парной корреляции более 0,85 в корреляционную модель предпочтительно не включать, как и такие, у которых связь с результативным параметром носит непрямолинейный или функциональный характер.
Отображение результатов
Результаты корреляционного анализа могут быть представлены в текстовом и графическом видах. В первом случае они представляются как коэффициент корреляции, во втором — в виде диаграммы разброса.

При отсутствии корреляции между параметрами точки на диаграмме расположены хаотично, средняя степень связи характеризуется большей степенью упорядоченности и характеризуется более-менее равномерной удаленностью нанесенных отметок от медианы. Сильная связь стремится к прямой и при r=1 точечный график представляет собой ровную линию. Обратная корреляция отличается направленностью графика из левого верхнего в нижний правый, прямая — из нижнего левого в верхний правый угол.
Трехмерное представление диаграммы разброса (рассеивания)
Помимо традиционного 2D-представления диаграммы разброса в настоящее время используется 3D-отображение графического представления корреляционного анализа.

Также используется матрица диаграммы рассеивания, которая отображает все парные графики на одном рисунке в матричном формате. Для n переменных матрица содержит n строк и n столбцов. Диаграмма, расположенная на пересечении i-ой строки и j-ого столбца, представляет собой график переменных Xi по сравнению с Xj. Таким образом, каждая строка и столбец являются одним измерением, отдельная ячейка отображает диаграмму рассеивания двух измерений.

Оценка тесноты связи
Теснота корреляционной связи определяется по коэффициенту корреляции (r): сильная — r = ±0,7 до ±1, средняя — r = ±0,3 до ±0,699, слабая — r = 0 до ±0,299. Данная классификация не является строгой. На рисунке показана несколько иная схема.

Пример применения метода корреляционного анализа
В Великобритании было предпринято любопытное исследование. Оно посвящено связи курения с раком легких, и проводилось путем корреляционного анализа. Это наблюдение представлено ниже.
Профессиональная группа | смертность |
|
Фермеры, лесники и рыбаки | ||
Шахтеры и работники карьеров | ||
Производители газа, кокса и химических веществ | ||
Изготовители стекла и керамики | ||
Работники печей, кузнечных, литейных и прокатных станов | ||
Работники электротехники и электроники | ||
Инженерные и смежные профессии | ||
Деревообрабатывающие производства | ||
Кожевенники | ||
Текстильные рабочие | ||
Изготовители рабочей одежды | ||
Работники пищевой, питьевой и табачной промышленности | ||
Производители бумаги и печати | ||
Производители других продуктов | ||
Строители | ||
Художники и декораторы | ||
Водители стационарных двигателей, кранов и т. д. | ||
Рабочие, не включенные в другие места | ||
Работники транспорта и связи | ||
Складские рабочие, кладовщики, упаковщики и работники разливочных машин | ||
Канцелярские работники | ||
Продавцы | ||
Работники службы спорта и отдыха | ||
Администраторы и менеджеры | ||
Профессионалы, технические работники и художники |
Начинаем корреляционный анализ. Решение лучше начинать для наглядности с графического метода, для чего построим диаграмму рассеивания (разброса).

Она демонстрирует прямую связь. Однако на основании только графического метода сделать однозначный вывод сложно. Поэтому продолжим выполнять корреляционный анализ. Пример расчета коэффициента корреляции представлен ниже.
С помощью программных средств (на примере MS Excel будет описано далее) определяем коэффициент корреляции, который составляет 0,716, что означает сильную связь между исследуемыми параметрами. Определим статистическую достоверность полученного значения по соответствующей таблице, для чего нам нужно вычесть из 25 пар значений 2, в результате чего получим 23 и по этой строке в таблице найдем r критическое для p=0,01 (поскольку это медицинские данные, здесь используется более строгая зависимость, в остальных случаях достаточно p=0,05), которое составляет 0,51 для данного корреляционного анализа. Пример продемонстрировал, что r расчетное больше r критического, значение коэффициента корреляции считается статистически достоверным.
Использование ПО при проведении корреляционного анализа
Описываемый вид статистической обработки данных может осуществляться с помощью программного обеспечения, в частности, MS Excel. Корреляционный предполагает вычисление следующих парамет-ров с использованием функций:
1. Коэффициент корреляции определяется с помощью функции КОРРЕЛ (массив1; массив2). Массив1,2 — ячейка интервала значений результативных и факторных переменных.
Линейный коэффициент корреляции также называется коэффициентом корреляции Пирсона, в связи с чем, начиная с Excel 2007, можно использовать функцию с теми же массивами.
Графическое отображение корреляционного анализа в Excel производится с помощью панели «Диаграммы» с выбором «Точечная диаграмма».
После указания исходных данных получаем график.
2. Оценка значимости коэффициента парной корреляции с использованием t-критерия Стьюдента. Рассчитанное значение t-критерия сравнивается с табличной (критической) величиной данного показателя из соответствующей таблицы значений рассматриваемого параметра с учетом заданного уровня значимости и числа степеней свободы. Эта оценка осуществляется с использованием функции СТЬЮДРАСПОБР (вероятность; степени_свободы).
3. Матрица коэффициентов парной корреляции. Анализ осуществляется с помощью средства «Анализ данных», в котором выбирается «Корреляция». Статистическую оценку коэффициентов парной корреляции осуществляют при сравнении его абсолютной величины с табличным (критическим) значением. При превышении расчетного коэффициента парной корреляции над таковым критическим можно говорить, с учетом заданной степени вероятности, что нулевая гипотеза о значимости линейной связи не отвергается.
В заключение
Использование в научных исследованиях метода корреляционного анализа позволяет определить связь между различными факторами и результативными показателями. При этом необходимо учитывать, что высокий коэффициент корреляции можно получить и из абсурдной пары или множества данных, в связи с чем данный вид анализа нужно осуществлять на достаточно большом массиве данных.
После получения расчетного значения r его желательно сравнить с r критическим для подтверждения статистической достоверности определенной величины. Корреляционный анализ может осуществляться вручную с использованием формул, либо с помощью программных средств, в частности MS Excel. Здесь же можно построить диаграмму разброса (рассеивания) с целью наглядного представления о связи между изучаемыми факторами корреляционного анализа и результативным признаком.